多线程
Parallelism and Concurrency
Concurrency 并发: A condition that exists when at least two threads are making progress. Single-core devices can achieve concurrency through time-slicing.
Parallelism 并行: A condition that arises when at least two threads are executing simultaneously. Multi-core devices execute multiple threads at the same time via parallelism.
Efficient parallel for-loop doing parallel computation across all CPU cores:
Context Switching
A context switch is when the CPU switches between these different subsystems or threads that make up your application.
Let's image that we only have one CPU remaining, the others are busy for some reason. At any time only one threads can run on that CPU. When the user touches the app, because the database is run off the main thread, the OS can immediately switch the CPU to work on the main thread, so it can respond immediately to the user without having to wait for the database thread to complete. When the user interface is done responding, the CPU can then switch back to the database thread, and then finish the networking task as well. These white lines below show the context switches.
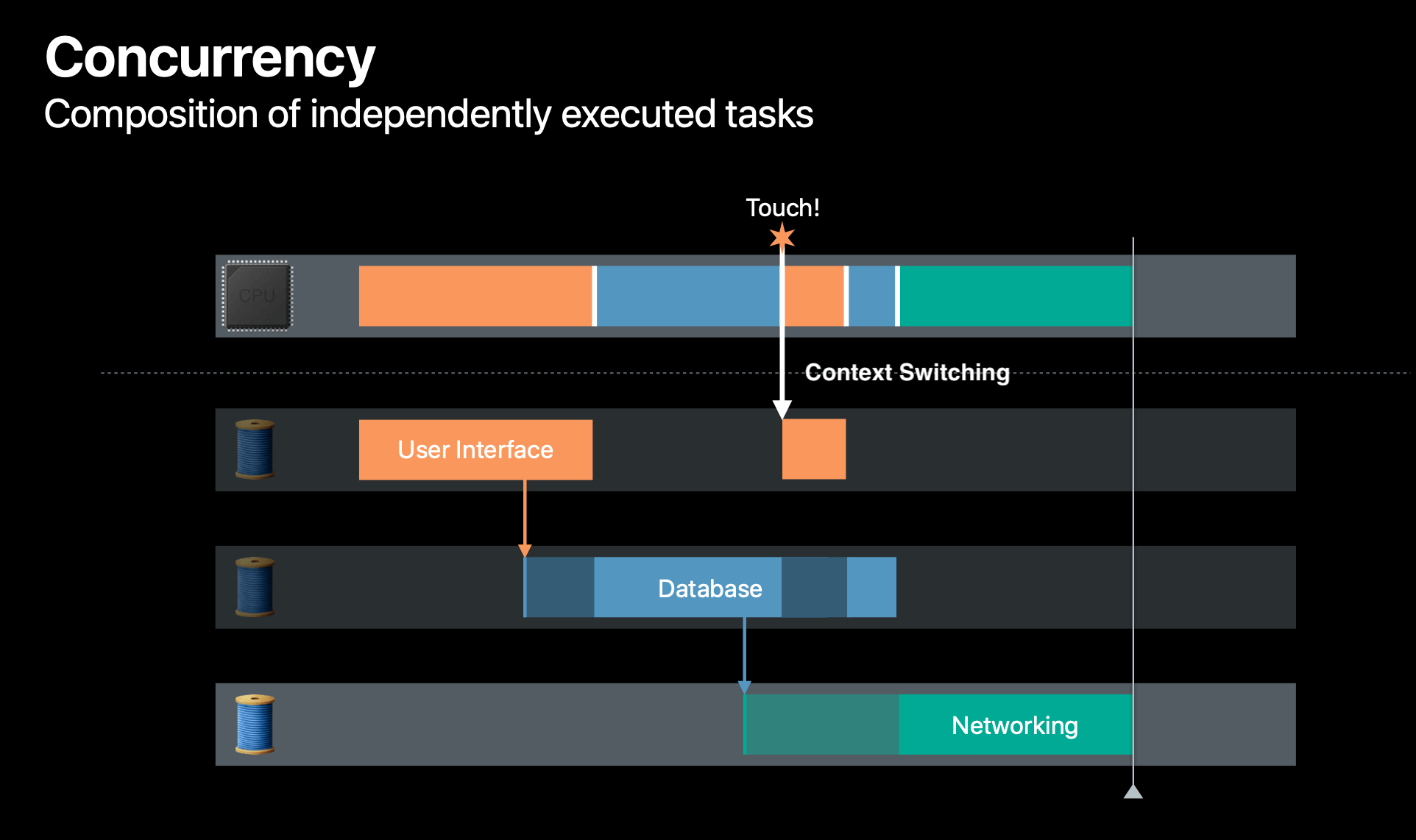
Context switches might happen when:
- A higher priority thread needs the CPU
- A thread finishes its current work
- Waiting to acquire a resource
- Waiting for an asynchronous request to complete
Excessive Context Switching: Context switch is good thing, it's where the power of concurrency comes from. However, if you're doing this thousands of times in really rapid succession, the costs start to add up and you run into trouble.
- Lock Contention: See below.
- Having too many serial queue: See below.
- Too many thread-blocking work items submiited to concurrent queue:
- Do not block thread;
- Choose the right amount of concurrency in your application;
- Size your work items appropriately.
Debug tool: Instruments - Template: Blank - Add Library: GCD Performance.
Lock Contention
The primary case of excessive context switching is lock contention, that happens when you have a lock and a bunch of threads are all trying to acquire that lock.
Let's see a fair lock case. Here we're focusing on two threads, and we have a CPU on top. We've added a lock track view that shows the state of the lock and what thread owns it.
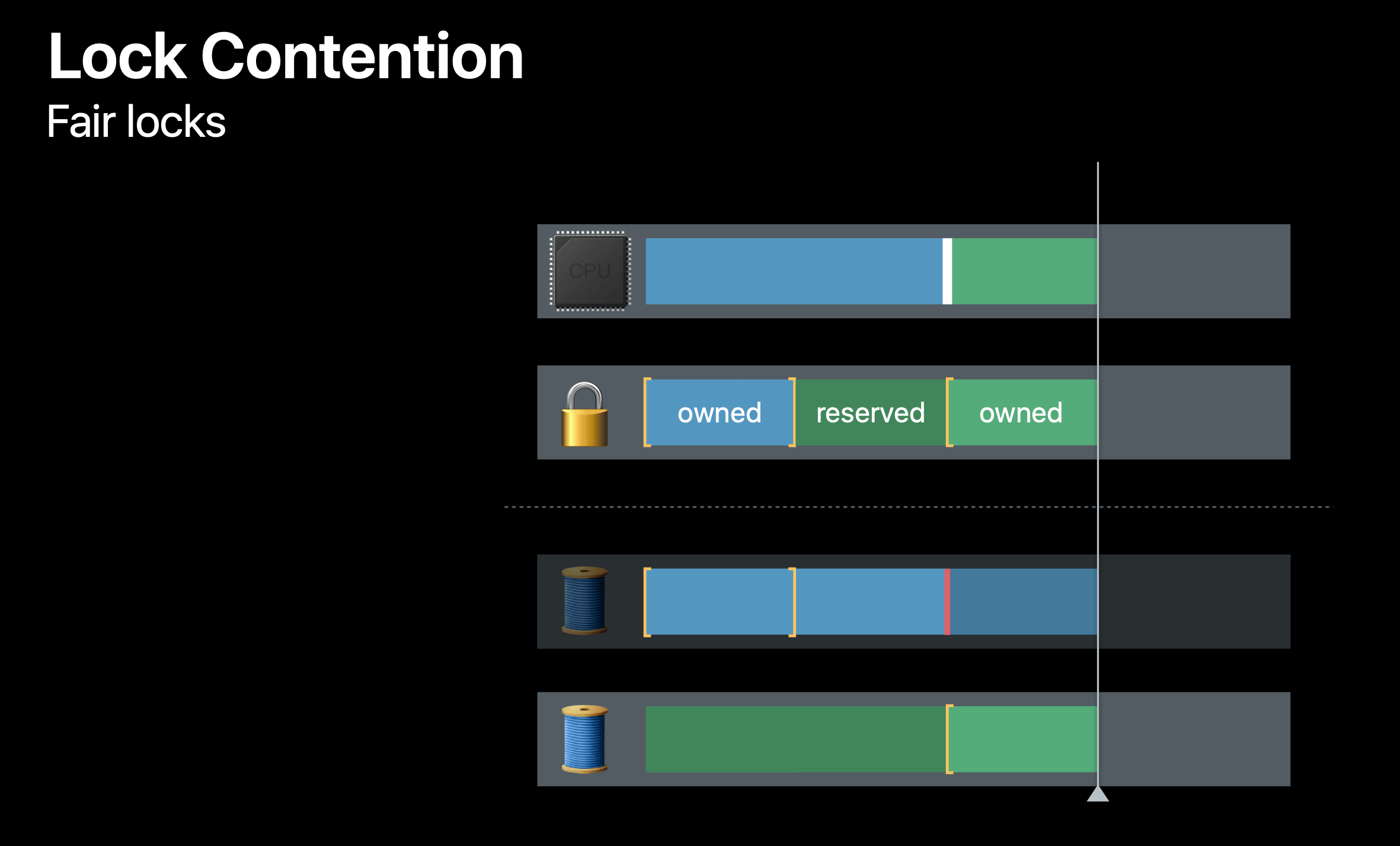
At the beginninbg, the blue thread owns the lock, and the green thread is waiting. Then, when the blue thread unlocks, the ownership of that lock is transferred to the green thread, because it's next in line, However, the CPU is still running the blue thread, and suppose, the blue thread grabs the lock again, it can't because the lock is reserved for the green thread. It forces a context switch at this point to the green thread.
The fair lock is useful. You want every thread that's waiting on the lock to get a chance to acquire the resource.
And the unfair lock case. This time, when blue thread unlocks, the lock isn't reserved. The ownership of the lock is up for grabs. Blue can take the lock again, and it can immediately reacquire and stay on CPU without forcing a context switch.
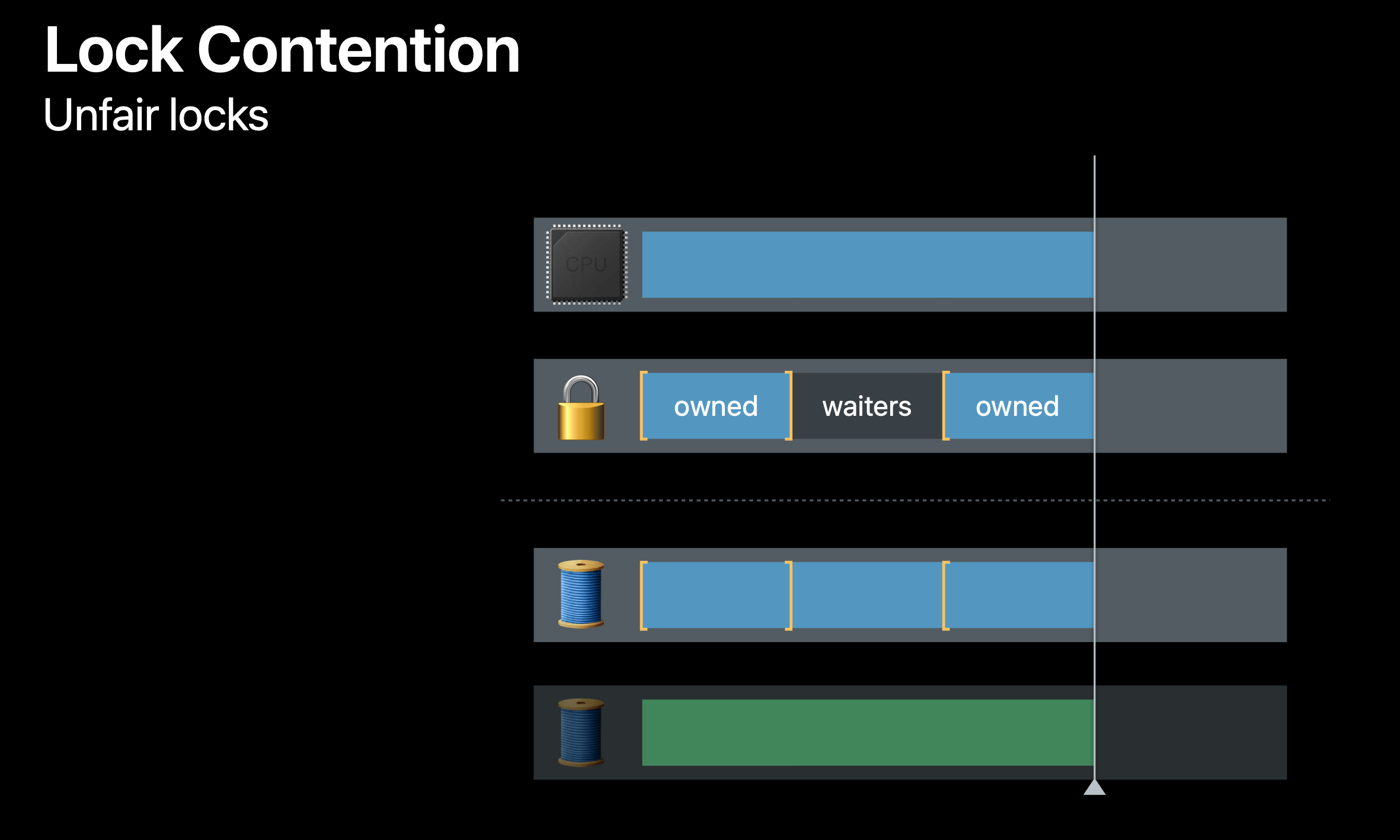
This might make it difficult for the green thread to actually get a chance at the lock, but it reduces the number of context switches the blue thread has to have in order to reacquire the lock.
You actually need to measure your application in "Instruments - System Trace" and see if you have an excessive context switching issue. If you do, often the unfair lock works best for these cases.

As you see the lock track view above, the runtime actually knows which thread will unlock the lock next. We can take advantage of that power to automatically resolve priority inversions between the waiters and the owners of the lock, and even enable other optimizations, like directed CPU handoff to the owning thread. Primitives with a single known owner have this power, but the others don't have.

So when you're picking a primitive (lock), consider whether or not your use case involves threads of different priorities interacting, like a high priority UI thread with a lower priority background thread. If so, you might want to take advantage of a primitive with ownership that ensures that your UI thread doesn't get delayed by waiting on a lower priority background thread.
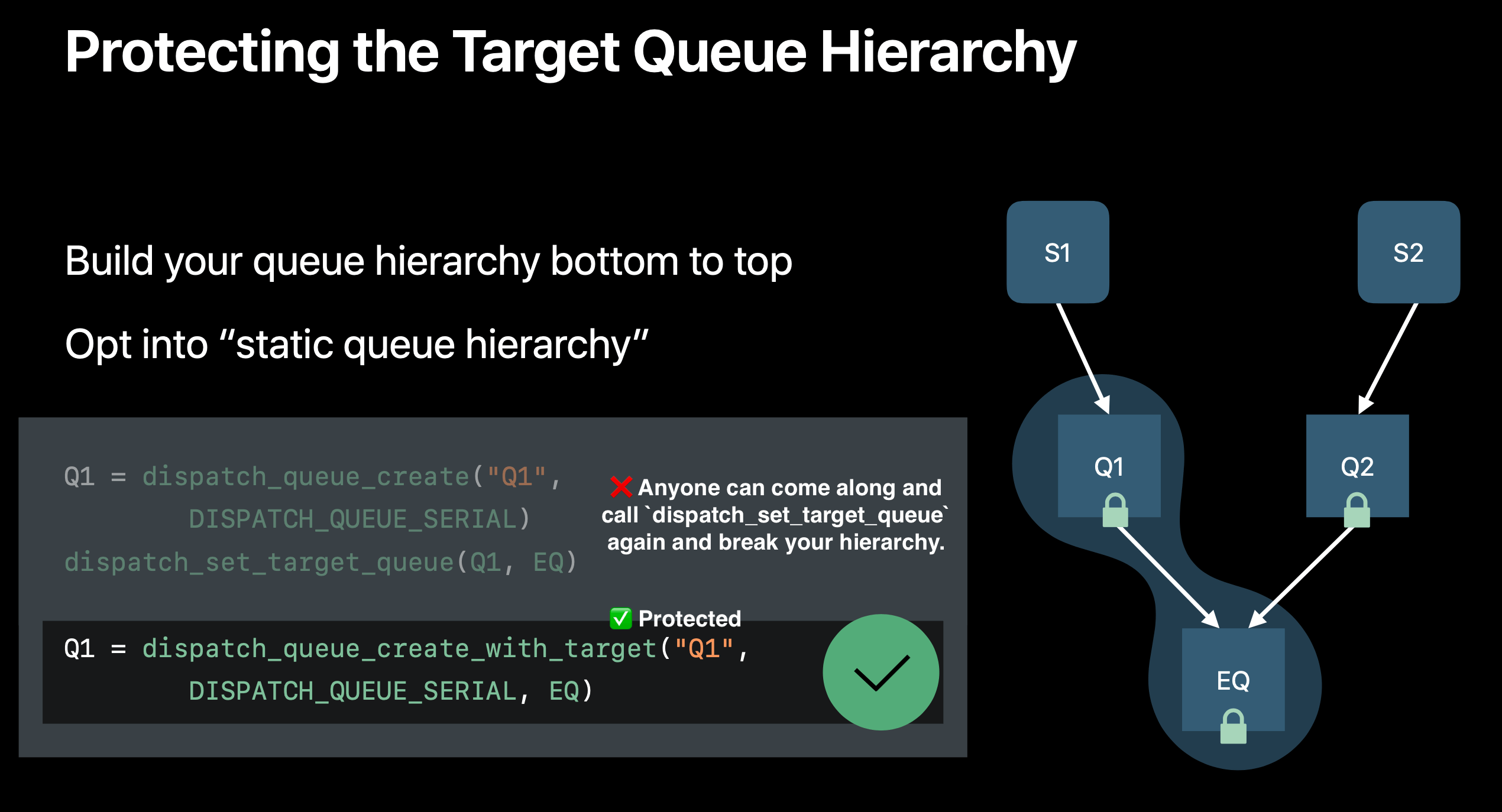
Target Queue Hirerachy
Set your serial queues targeting one queue per subsystem, use a fixed number of serial queue hierarchies.

We have completely reinvented the internals of GCD this year to eliminate some unwanted context switches and execute single queue hierarchies on the single thread. You, as the developer, need to protect the target queue hierarchy so your code can be benefited from these optimizations.
Operation
OperationQueue:
- High-level
dispatch_queue_t - Cancellation
maxConcurrentOperationCount, 1 means serial queue
Operation:
- High-level
dispatch_block_t - Long-running task
- Subclassable
@property(readonly, getter=isCancelled) BOOL cancelled; Cancellation on Operation only flipped the boolean value of cancelled. So as you subclass Operation, it is up to you to decide what it means for your Operation to be canceled.
@property(readonly, getter=isReady) BOOL ready; By default, an operation will become ready if all of its dependencies have finished executing. If you have two operation queues in your application, operations in the first queue can be dependent on the operations in the second queue. 先进入 ready 状态的任务先出列执行、不管其在队列中的哪个位置。OperationQueue 并不是 FIFO 的队列!
Use operations to abstract the logic in your app. By putting your logic inside of operations, it becomes very easy to change it later. Use dependencies to express the relationships between your operations. Next, operations allow you to describe complex behaviors, such as mutual exclusivity or composition.
Synchronization
多个进程同时操作同一份数据、并且执行结果取决于操作发生的特定顺序的情况,称为竞争情况 (race condition)。为了防止出现竞争情况,我们要求以某种方式同步 (synchronized) 进程。
每个线程会有自己的栈内存空间,栈空间相互隔离、互不影响;但有时多个线程要访问到共享的堆区内存,此时如果不进行同步,就会出现内存不一致问题。设想这样一个场景,用户的银行账户里有 100 元,此时有 3 个柜员机同时进行存、取、查操作,它们之间就需要进行同步。
程序可以声明称为临界区 (critical section) 的代码。在临界区中,线程可能正在访问或更新与至少一个其他线程共享的数据。当一个线程在临界区执行时,不允许其他线程在临界区执行。多个线程必须互斥地对临界资源进行访问。
公平锁与非公平锁
多个线程同时到达临界区,先到的线程会获得锁,后到的线程会在一个 FIFO 队列里等待。
公平锁:在竞争情况下,锁被释放后,即被等待队列头部的线程保留。优点是每个线程都有机会得到锁,不会饿死;缺点是由于上下文切换次数更多、相对来说吞吐量没有非公平锁大。
非公平锁:在竞争情况下,锁被释放后不会被保留,无须考虑等待队列里的线程。优点是提高了重获锁的效率和整体的吞吐量;缺点是可能导致别的线程一直获取不到锁、甚至饿死。
iOS 中日常使用到的锁,除了 os_unfair_lock 是非公平锁,其余都是公平锁。
为什么要进入队列等待呢?一直尝试获取锁可以吗?——可以,一直尝试获取的叫自旋锁,与互斥锁类似,只是自旋锁被某线程占用时,其他线程不会挂起,而是一直运行(自旋/空转)直到锁被释放。由于不涉及用户态与内核态之间的切换,它的效率高于互斥锁。但相应地,会一直占用 CPU,如果不能在很短的时间内获得锁,无疑会使 CPU 整体效率降低。
非公平锁/自旋锁适用于:预计临界区执行的时间很短,等待的线程能很快获得锁;临界区的代码经常被调用,但竞争情况很少发生。
公平锁/互斥锁适用于:预计临界区执行的时间较长,线程等待锁的时间较长;临界区竞争情况经常发生。
os_unfair_lock
#import <os/lock.h>
os_unfair_lock lock = OS_UNFAIR_LOCK_INIT;
os_unfair_lock_lock(&lock); // 加锁和解锁必须对称,重复加锁会直接崩溃!
NSLog(@"safe here ...");
os_unfair_lock_unlock(&lock);
A lock must be unlocked only from the same thread in which it was locked. Attempting to unlock from a different thread causes a runtime error.
This is a replacement for the deprecated OSSpinLock. This function doesn't spin on contention, but instead waits in the kernel to be awoken by an unlock. Like OSSpinLock, this function does not enforce fairness or lock ordering—for example, an unlocker could potentially reacquire the lock immediately, before an awoken waiter gets an opportunity to attempt to acquire the lock. This may be advantageous for performance reasons, but also makes starvation of waiters a possibility.
互斥锁
pthread_mutex_t,pthread 中的互斥锁,具有跨平台性质,有普通锁、检错锁、递归锁三种。当锁处于占用状态时,其他线程会挂起;当锁被释放时,所有等待的线程都将被唤醒,再次对锁进行竞争。在挂起与唤醒过程中,涉及用户态与内核态之间的上下文切换,这种切换是比较消耗性能的。
NSLock 是对 pthread_mutex_lock 的封装,是普通类型的互斥锁;如果用在需要递归嵌套加锁的场景时,需要使用其子类 NSRecursiveLock。
@synchronized 是对 pthread_mutex_t 的封装,是递归类型的互斥锁。
@synchronized (self) {
callbacks = [[self.callbackBlocks valueForKey:key] mutableCopy];
}
pthread_rwlock_t 读写锁是用于“多线程读、单线程写”这一种读写互斥的场景,读操作可并发重入,写操作是互斥的。
#import <pthread/pthread.h>
- (instancetype)init {
self = [super init];
if (self) {
pthread_rwlock_init(&_lock, nil);
}
return self;
}
- (void)queryMoney {
pthread_rwlock_rdlock(&_lock);
[super queryMoney];
pthread_rwlock_unlock(&_lock);
}
- (void)saveMoney {
pthread_rwlock_wrlock(&_lock);
[super saveMoney];
pthread_rwlock_unlock(&_lock);
}
信号量
信号量主要用于控制临界区的资源最多可以被多少个线程并发访问。
dispatch_semaphore_t lock = dispatch_semaphore_create(1);
dispatch_semaphore_wait(lock, DISPATCH_TIME_FOREVER); // 等待和发出信号必须对称!重复调用 wait 不会崩溃,但会造成无限的等待……
NSLog(@"safe here ...");
dispatch_semaphore_signal(lock);
OSSpinLock (deprecated)
在罕见的情况下,低优先级的线程先获得了锁,这时一个高优先级的线程也尝试获得这个锁,它会处于空转状态并持续占用 CPU。但与此同时,低优先级线程在 CPU 时间的分配上远远少于高、中优先级线程,这就导致任务迟迟完不成、无法释放锁。除非开发者能保证访问锁的线程全部处于同一优先级,否则 iOS 系统中所有类型的自旋锁都不能再使用了。
过去 atomic 修饰的属性在底层也是使用自旋锁的,随着自旋锁被废弃,现在改用了 os_unfair_lock。
原子操作
某些简单的表达式例如 i += 1,其实编译之后的得到的汇编指令,不止一条,所以他们并不是原子操作。
原子操作一定是在同一个 CPU 时间片中完成,这样即使线程被切换,多个线程也不会看到同一块内存中不完整的数据。
IPC 跨进程通信
由于 iOS 的沙盒机制,每个进程都在独立的沙盒中运行,与其它进程的通信相对受限,主要是通过系统的接口。例如:
UIDocumentInteractionController 可以传输文档、预览、打印、发邮件等,参考 iOS SDK: Previewing and Opening Documents。
UIActivityViewController 提供了分享内容的方法,包括 AirDrop 等。
UIPasteboard 可以访问剪贴板。
Keychain 提供钥匙串访问。
访问 Application Group 共享的文件夹:FileManager.default.containerURL(forSecurityApplicationGroupIdentifier: kAppGroupIdentifier)。
在共享区存储 UserDefaults:UserDefaults(suiteName: kAppGroupIdentifier)。
URLScheme 和 Universal Links 通过深链接 URL 传递信息。
macOS 上还可以通过 local socket,进程 A 对某一个端口进行绑定、监听,进程 B 进行 TCP 连接。参考:Inter-Process Communication(不仅是 iOS,也有 macOS,针对整个苹果生态)。
死锁
简单的死锁例子:
import Foundation
let lock = NSLock()
func methodA() {
lock.lock();
methodB()
lock.unlock();
}
func methodB() {
lock.lock();
print("B")
lock.unlock()
}
methodA()
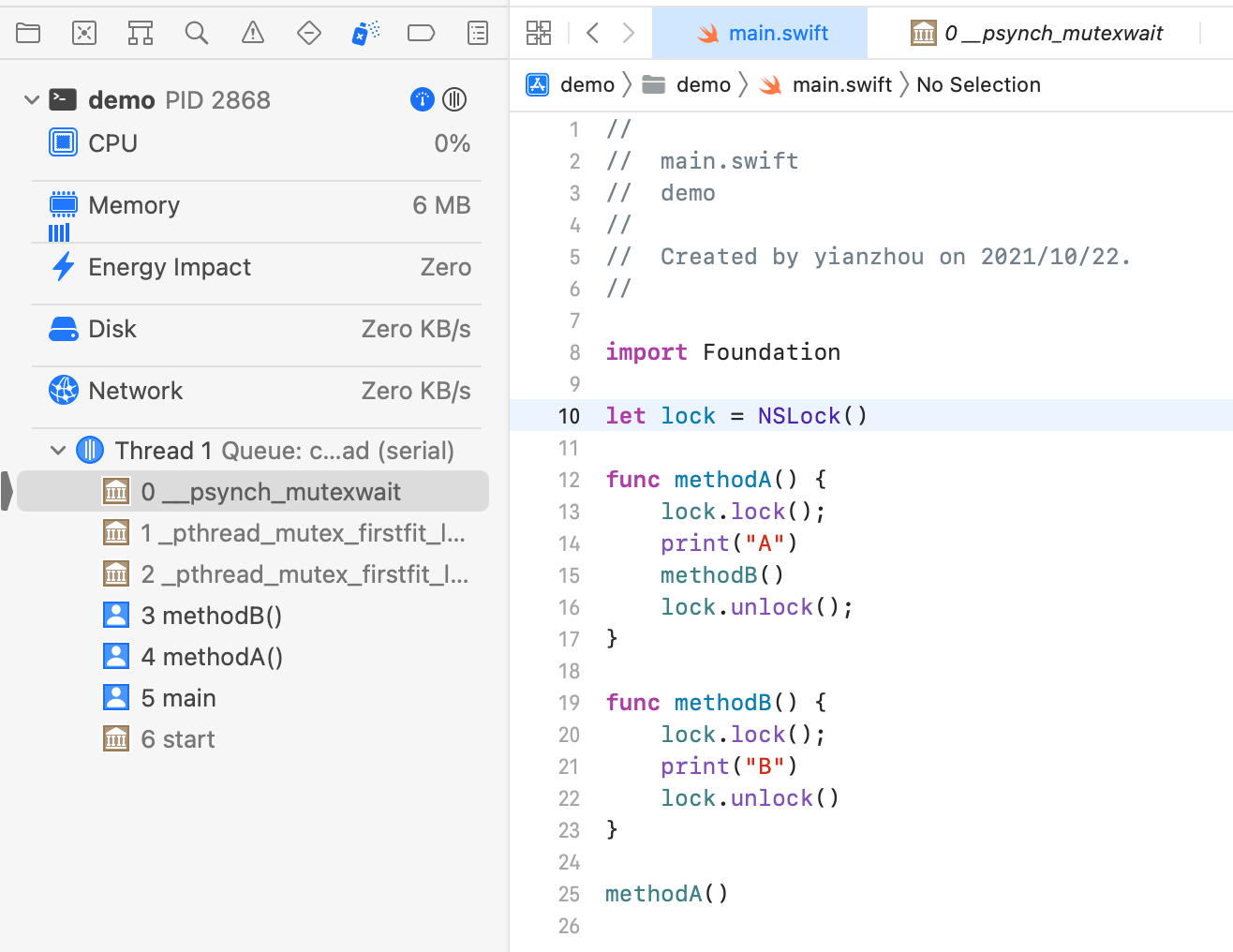
NSLock 是非递归锁,当同一线程重复获取同一非递归锁时,就会发生死锁。
递归锁:它允许同一线程多次加锁,而不会造成死锁。所以上面的代码改成 NSRecursiveLock 后不会死锁。
但如果错误地在两个线程中使用了递归锁,则很容易导致死锁:两个线程同时对同一个锁进行加锁,同时发现该锁已经锁定,彼此等待对方解锁,导致两个线程都无法执行下去。尤其是有一方是主线程的情况下,主线程被阻塞,UI 呈现假死状态。
递归锁专门用于循环或递归中需要同步的代码,但它却不能避免两个线程同时访问锁中代码的情况。而 NSLock 却恰恰相反,它能避免两个线程同时访问锁中的代码,却不能避免在同一线程中,同步代码中嵌套加锁的情况。
如果因为代码中既没有递归也没有循环,则用 NSLock。
单例与线程安全
单例中读写静态变量,不安全。
static bool hasDone = NO;
if (!hasDone) {
// do something
hasDone = YES;
}
以上写法不安全,有可能多个线程同时通过非空检查,导致 if 内的代码执行多次。
懒加载在单例中不安全。
- (NSArray *)myArray {
if (_myArray) {
_myArray = [[NSArray alloc] init];
}
return _myArray;
}
这种判断在多线程下不安全的。多线程下尽量别使用懒加载,即使使用,也要加相应的保护,比如在 _myArray 不会被重新置为 nil 的前提下可以使用 dispatch_once。