C++ Primer
Hello world
Clang 是苹果官方的用来编译 C 家族的编译器,它是 LLVM 的一部分。相比于 Xcode 5 版本前使用的 GCC 有多项优化。
编译:clang++ main.cpp
编译 C++11:clang++ -std=c++11 main.cpp
文件重定向:./a.out <infile >outfile
<< 是输出运算符,>> 是输入运算符。
endl 是操纵符 (manipulator),写入 endl 的效果是结束当前行,并将设备关联的 buffer 中的内容刷新到设备中。缓冲刷新操作可以保证内存中的数据都真正写入到输出流中。
:: 是作用域运算符。
#include <iostream>
int main() {
int sum = 0, value = 0;
// 以 istream 对象的状态作为检测条件
// 当遇到 end-of-file (ctrl+D) 或无效输入(输入的值不是一个整数),istream 状态就会变为无效
while (std::cin >> value) {
sum += value;
}
std::cout << "Sum is " << sum << std::endl;
return 0;
}
编译并链接:clang++ main.cpp fact.cpp,产出 a.out 文件。
等价于下面的步骤(分离式编译):
- 只编译:
clang++ -c main.cpp,产出main.o文件。 - 只编译:
clang++ -c fact.cpp,产出fact.o文件。 - 链接:
clang++ main.o fact.o,产出a.out文件。
## is called token concatenation, used to concatenate two tokens in a macro invocation.
#define Flutter_CONCAT2(A, B) A##B
#define Flutter_CONCAT(A, B) Flutter_CONCAT2(A, B)
从标准输入流中获取每一行:
string line;
while (getline(cin, line))
if (!line.empty())
cout << line << endl;
变量和基本类型
溢出
int main(int argc, const char * argv[]) {
// char 可以表示 [-128, 127] 之间的数
char c1 = -128;
printf("%d\n", c1); // -128 (0x80, 0b10000000)
char c2 = 127;
printf("%d\n", c2); // 127 (0x7f, 0b01111111)
char c3 = -129;
printf("%d\n", c3); // 127 (0x7f, 0b01111111)
char c4 = 128;
printf("%d\n", c4); // -128 (0x80, 0b10000000)
return 0;
}
模除
模除(又称模数、取模):The modulo operator, denoted by %, produces the remainder of an integer division.
Modulo Operator (%) in C/C++ with Examples - GeeksforGeeks
模除的两个操作数都只能是整型,不能是浮点类型。
对于操作数为负数的情况,模除结果的符号取决于机器,因为该操作是下溢或上溢的结果。
int main(int argc, const char * argv[]) {
// 正整数模除
printf("%d\n", 3 % 4); // 3
printf("%d\n", 4 % 3); // 1
printf("%d\n", 4 % 2); // 0
// 负数模除
printf("%d\n", -3 % 4); // -3
printf("%d\n", 4 % -2); // 0
printf("%d\n", -3 % -4); // -3
return 0;
}
基本内置类型
无符号类型中所有位都用于存值;有符号类型,C++标准并没有规定如何存储,但约定了负值与正值间尽量平衡。
关于类型转换:
- 当我们把一个非布尔类型的算术值赋给布尔类型时,初始值为 0 则结果为 false,否则结果为 true。
- 当我们把一个布尔值赋给非布尔类型时,初始值为 false 则结果为 0,初始值为 true 则结果为 1。
- 当我们赋给无符号类型一个超出它表示范围的值时,结果是初始值对无符号类型表示数值总数的模除。例如,8 位的
unsigned char可以表示 256 个数。如果我们赋了一个区间以外的值,则实际的结果是该值对 256 取模后的余数。因此,把 -1 赋给unsigned char所得的结果是 255。 - 当我们赋给带符号类型一个超出它表示范围的值时,结果是未定义的 (undefined)。此时,程序可能继续工作、可能崩溃,也可能生成垃圾数据。
int main(int argc, const char * argv[]) {
bool b = -1;
printf("%s\n", b ? "true" : "false"); // true
unsigned char c = -1;
printf("%d\n", c); // 255(0xFF,所有位都是1)
return 0;
}
切勿混用带符号类型和无符号类型!!
unsigned u = 0;
int i = -1;
std::cout << u + i << std::endl; // 4294967295,2^32 = 4294967296
每个字面值常量 (literal) 都对应一种类型,字面量的形式和值决定了它的数据类型。
整型:
// 下面三个数都表示 20
int a = 20; // 十进制
int a = 024; // 0 开头的整数表示八进制数
int a = 0x14; // 0x 或 0X 开头的整数表示十六进制数
// 最小匹配类型就是能容纳这个字面量的、尺寸最小的类型
int a = 10; // 最小匹配类型 int
unsigned int a = 10u; // 最小匹配类型 unsigned
long a = 10L; // 最小匹配类型 long
unsigned long a = 10UL; // 最小匹配类型 unsigned long
C++ 14 标准里新增了二进制类型:
int x = 0b00010000;
浮点型:
double b = 3.14; // 浮点型默认是 double
float b = 3.14f;
long double b = 3.14L;
double b = 10.;
double b = 10e-2; // 指数部分用 e 或 E 表示
long double b = 3.14e0L;
字符和字符串字面量:
char c = 'a'; // 字符
wchar_t c = L'a'; // 宽字符
char s[] = "a"; // 字符串字面量的类型实际上是字符构成的数组
cout << strlen(s) << endl; // 1
// 对于 C 数组,C++ 没有提供方法直接计算其长度,可以借助 sizeof()、begin()、end() 间接计算其长度。
// 编译器会在字符数组结尾添加一个空字符 '\0',因此数组长度会比它的内容多 1
int length = sizeof (s) / sizeof (s[0]);
cout << length << endl; // 2
int length2 = std::end(s1) - std::begin(s1);
cout << length2 << endl; // 2
wchar_t s[] = L"abc"; // 宽字符数组
转义字符:
// \ 后面跟着八进制数字、\x 后面跟着十六进制表示转义字符
char c = '\10';
char c = '\x4d';
变量
定义一个变量并初始化:
// C++98
int units_sold1 = 1;
int units_sold2 = {2};
int units_sold3(3);
// C++11
int units_sold4{4}; // 用花括号初始化的形式称为列表初始化 (list initialization)
列表初始化时如果存在丢失信息的风险,编译器会报错:
long double ld = 3.1415926;
int a(ld), b = ld; // 可以编译
int c{ld}, d = {ld}; // ❌ 报错
函数体内的内置类型变量如果没有初始化,则其值未定义;类的对象没有显式初始化,其值由类的默认构造函数确定。
分离式编译指的是允许将程序分为多个文件,每个文件独立编译。为了支持分离式编译,C++ 将声明 (declaration) 与定义 (definition) 区分开。变量的定义只能出现在一个文件中,其它用到该变量的文件必须对其进行声明。
extern int i; // 声明 i
int j; // 声明并定义 j
作用域可以嵌套,外层的叫 outer scope,内层的叫 inner scope。
void test() { // 名字 test 拥有全局作用域 (global scope)
int sum = 0; // 名字 sum 拥有块作用域 (block scope)
}
引用
目前我们接触到的变量声明,由一个基本数据类型 + 一个变量名组成。现在我们学习更复杂的声明,它基于基本数据类型得到更复杂的类型。
引用即别名,是已存在的对象的另一个名字。引用必须被初始化!定义引用时,程序把引用和它的初始值绑定在一起。无法令引用重新绑定到另一个对象!
int ival = 1024;
int &refVal = ival; // ✅ refVal 指向 ival(是 ival 的另一个名字)
int &refVal2; // ❌ 引用必须被初始化!
int &refVal3 = refVal // ✅ 将 refVal3 也绑定到 ival 上
定义了引用之后,操作引用就是操作它绑定的对象!
refVal = 2048;
std::cout << ival << std::endl; // 2048
int i = 10, &r1 = i;
double d = 3.14, &r2 = d;
r2 = r1; // 等价于 d = i;
std::cout << d << std::endl; // 10
r1 = 20;
r2 = 31.4;
std::cout << i << " " << d << std::endl;
引用本身不是一个对象,不能定义引用的引用。
引用必须绑定一个对象,不可以绑定一个 literal 或者表达式的计算结果。
int &ref2 = 10; // ❌
int &ref3 = 10 + 10; // ❌
指针
A reference refers to another type. A pointer points to another type. 引用本身不是一个对象;指针本身是一个对象,允许对指针进行赋值和拷贝。
引用一旦定义,就绑定了它初始化的对象,无法令其绑定到其它的对象;指针无须在定义时初始化,可以随时给它赋值一个新的地址,指向一个新的对象。
指针用于存放某个对象的地址。获取对象的地址,用取地址符 &。指针的类型,要和它指向的对象类型严格匹配!
int ival = 42;
int *pt = &ival; // pt 存放 ival 的地址,或者说 pt 是指向 ival 的指针
如果指针指向了一个对象,那么可以使用解引用符 * 来访问该对象。
std::cout << *pt << std::endl;
& 出现在声明中,代表引用;出现在表达式中,代表取地址符!
* 出现在声明中,代表指针;出现在表达式中,代表解引用符!
int i = 10; // 声明并定义 i,并初始化它的值为 10
int &r = i; // r 是一个引用,即 i 的一个别名
int *p; // p 是一个指向 int 类型的指针
p = &i; // 取 i 的地址,赋值给 p,p 指向 i
*p = i; // 将 i 的值赋值给 p 指向的对象
int &r2 = *p; // 定义引用类型 r2 并绑定到 p 指向的对象
int j = 42, *p2 = &j;
int *&pref = p2; // pref is a reference to the pointer p2
// prints the value of j, which is the int to which p2 points
std::cout << *pref << std::endl;
// pref refers to a pointer; assigning &i to pref makes p point to i
pref = &i; // 引用不可以绑定到别的对象,但指针可以随时改变指向
std::cout << *pref << std::endl; // prints the value of i
空指针不指向任何对象,在试图使用一个指针之前,应该检查它是否为空。NULL 是预处理变量 (preprocessor variable),定义在 cstdlib,它的值就是 0;预处理器 (preprocessor) 是运行于编译之前的一段程序。在现行标准下,最好使用 nullptr,避免使用 NULL。
int *p1 = nullptr; // literal
int *p2 = 0; // literal
int *p3 = NULL;
0 指针的条件值是 false;非 0 指针的条件值是 true。
int *pi1 = 0;
int *pi2 = &ival;
if (!pi1) {
std::cout << pi1 << std::endl; // 0x0
}
if (pi2) {
std::cout << pi2 << std::endl;
}
void * 是一种特殊的指针,它可以存放任意对象的地址。
double obj = 3.14;
void *pv = &obj;
指针�的指针:指针是内存中的对象,和其它对象一样也有自己的地址,因此可以将指针的地址再存放到另一个指针中。
int **ppi = &pi2; // ppi -> pi2 -> ival
const 限定符
const 修饰的变量,其值不可改变。
默认状态下,const 对象仅在本文件内有效。想在多个文件之间共享 const 对象,必须在变量定义前添加 extern 关键字。
#include <iostream>
const int bufSize = 512; // 本文件内有效
extern const int bufSize2 = 512;
int main() {
return 0;
}
const 对象必须初始化:const int k; // ❌
Reference to const
绑定到常量对象需要声明 reference to const:
const int ci = 1024;
const int &r1 = ci;
r1 = 42; // ❌ ci 是一个常量,不能被修改
int &r2 = ci; // ❌ 普通引用不能绑定到常量对象
初始化 reference to const 时允许用任意表达式作为初始值,只要该表达式可以转换为引用的类型。
int i = 42;
const int &r1 = i;
const int &r2 = 42; // ✅ 允许 const int& 绑定到字面值
const int &r3 = r1 * 2; // ✅
注意引用绑定中的隐式转换。
double dval = 3.14;
const int &r6 = dval; // 由于 r6 的类型是整数,实际上绑定到了一个临时对象 const int temp = dval;
dval = 10.24;
std::cout << r6 << std::endl; // 3
允许 reference to const 引用非常量对象:
int i = 42;
const int &r = i; // ✅ 允许 const int& 绑定到普通 int 对象上,但不能通过 r 修改变量 i 的值
i = 84; // 虽然不能通过 r 修改变量 i 的值,但 i 毕竟不是常量,可以通过其它途径修改
std::cout << r << std::endl; // 84
Pointer to const, const pointer
要想存放常量对象的地址,只能使用指向常量的指针 (pointer to const):
const double pi = 3.14;
const double *cptr = π
允许 pointer to const 指向非常量,pointer to const 只是要求不能通过本指针改变所指对象的值,但那个所指对象的值可以通过其他途径改变。
double dval = 3.14;
cptr = &dval;
dval = 10.0
const pointer 是不会改变指向的指针,它一旦初始化,就永远指向那个对象。const pointer 必须被初始化。
int errNumb = 0;
int *const curErr = &errNumb;
const double pi2 = 3.14159;
const double *const pip = &pi2; // 弄清楚声明的含义,最好的方式是从右向左读:pip is a const pointer to const double
Top-level const and low-level const
const pointer (top-level const): 指针本身是一个常��量。
pointer to const (low-level const): 指针所指的对象是一个常量。
更一般地,顶层 const 可以表示任意数据类型的对象是常量;底层 const 则与指针、引用等复合类型的基本类型部分有关。
int i = 0;
int *const p1 = &i; // top-level const
const int ci = 42; // top-level const
const int *p2 = &ci; // low-level const
const int &r = ci; // low-level const
const int *const p3 = p2; // top-level and low-level const
它们的区别主要体现在拷贝操作时。top-level const 不存在限制;low-level const 则存在一些限制。非常量可以转为常量,反之则不行。
int *p = p2; // ❌
int &r2 = ci; // ❌
constexpr
常量表达式是指在编译过程中就能计算出结果的表达式。
C++11 允许将变量声明为 constexpr 以便编译器验证变量值是否是一个常量表达式。
如果你肯定变量是一个常量表达式,那就把它声明成 constexpr 吧!
constexpr int mf = 20;
constexpr int limit = mf + 1;
声明 constexpr 时用到的类型是字面值类型 (literal type),算术类型、指针、引用、字面值常量类、枚举类型都属于字面值类型;自定义的类、IO 库、string 类型不是字面值类型。
函数体��内的变量并非存放在固定地址,因此 constexpr 指针不能指向这样的变量。定义于所有函数体之外的对象,其地址固定不变,可以用来初始化 constexpr 指针。
constexpr 修饰的指针是常量指针,指的是编译期就能够知道这个指针指向哪里。constexpr 指针既可以指向常量也可以指向非常量。
const int *p = nullptr; // p 是 pointer to const
constexpr int *q = nullptr; // q 是 const pointer
类型别名
typedef double wages;
typedef double *dptr;
typedef char *pstring;
wages i = 3.14;
dptr p = &i;
char c = 'c';
pstring cstr = &c;
编写头文件
头文件通常包含那些只能被定义一次的实体,比如 class, struct, const, constexpr。
头文件被多次包含(显式或隐式)会带来问题,确保头文件被多次包含仍能安全工作的技术是 preprocessor。
整个程序中的预处理变量必须唯一,通常做法是用头文件的名字大写来保证唯一性。
#ifndef SALES_DATA_H
#define SALES_DATA_H
#include <string>
// 类所在的头文件名字应与类一样
struct Sales_data {
std::string bookNo;
unsigned units_bold = 0; // C++11 in-class initializer
double revenue = 0; // C++11 in-class initializer
};
#endif
字符串、向量、数组
string
字符串直接初始化:
// direct initialization
string s1; // ""
string s2(10, 'c');
string s3(s1);
string s4("value");
字符串拷贝初始化:编译器把等号右侧的初始值,拷贝到新创建的对象中去。
string s = string(10, 'c');
// 等价于
string temp(10, 'c');
string s = temp;
string s = "hiya";
// 等价于
string temp("hiya");
string s = temp;
string 类和其它大多数标准库类型,都定义了几种配套的类型,例如 size_type。这些配套类型体现了标准库类型与机器无关的特性。
std::string::size_type size = line.size();
由于历史原因,为了与 C 兼容,字符串字面值不是 C++ 的 string 对象,而是字符数组,因此不能把字面值直接相加。
string s2 = s1 + " hello"; // ✅ string 对象与字面值相加
string s = "Hello" + " world!"; // ❌
C++ 标准库兼容了 C 标准库,C 语言的 ctype.h 文件,C++ 命名为 cctype,即去掉 .h 后缀,加上 c 前缀,使其符合 C++ 命名规范。
#include <cctype>
// 标准库的一些函数
using std::isupper; using std::toupper;
using std::islower; using std::tolower;
using std::isalpha; using std::isspace;
char c = 'c';
bool b = isalpha(c);
cout << b << endl;
使用 for 语句操作字符串,注意值传递和引用传递的区别:
// 每次迭代,变量 c 被初始化为 str 的下一个元素�值
for (const char c : str)
cout << c << endl;
// 使用引用类型作为循环变量,每次迭代引用会绑定到序列的每个元素上
for (char &c : str)
c = toupper(c);
cout << str << endl;
vector
模板的作用是,告诉编译器如何生成类或函数。编译器根据模板生成类或函数的过程,称为实例化 (instantiation)。
C++ 既有类模板,也有函数模板。vector 是类模板 (class template)。
vector 是对象的集合,�也称为容器。我们通过提供一些额外的信息,来指定模板实例化成什么样的类。对于 vector 这个类模板来说,提供的额外信息是 vector 内存放对象的类型。提供信息的方式是,在模板名字后面加上尖括号。
int n = 5; // 元素个数
vector<int> v1;
vector<int> v2(v1); // v2 中包含有 v1 所有元素的副本
vector<int> v3 = v1; // 同上
vector<int> v4(n, 100);
vector<int> v5(n);
vector<int> v6{1, 2, 3, 4, 5}; // C++11
vector<int> v7 = {1, 2, 3, 4, 5}; // C++11
vector<vector<int>> ivec;
vector<string> v8{10}; // 10 个空字符串
for (int i = 0; i < 5; ++i) {
v1.push_back(i);
}
// for-in 语句体内不能有会改变容器 size 的操作
// 打印 vector 中的所有元素
for (auto i : dp)
std::cout << i << ',';
迭代器
vector<int> vec(10, 100);
// end 返回的迭代器称为“尾后迭代器”,指向尾元素的下一位置
for (vector<int>::iterator it = vec.begin(); it != vec.end(); ++it) {
*it = *it * 2;
}
// 不需要修改 vector 内元素的话,建议用 const_iterator
// 与 for-in 语句一样,使用迭代器的循环体内不能改变容器的 size!
for (auto it = vec.cbegin(); it != vec.cend(); ++it) {
cout << it->mem << endl;
}
箭头运算符 -> 把解引用和访问成员两个操作结合在一起:it->mem 等价于 (*it).mem。
内置数组
数组与 vector 很相似,但数组的大小是固定的,需要通过元素的下标来访问。
const unsigned sz = 3;
int ial[sz] = {0, 1, 2};
int a[] = {0, 1, 2};
int a2[5] = {0, 1, 2}; // [0, 1, 2, 0, 0]
string a3[3] = {"hi", "bye"};
const unsigned size = 10;
int arr[size];
for (int *ptr = arr; ptr < arr + size; ++ptr) {
*ptr = 10;
}
不能将数组的内容拷贝给其它数组作为初始值,也不能用数组为其它数组赋值。
int a2[] = a; // ❌
复杂的数组声明:
int arr[10] = {0};
int *ptrs[10]; // 含有 10 个整型指针的数组
int(*Parray)[10] = &arr; // Parray 指向含有 10 个整数的数组
int(&arrRef)[10] = arr; // arrRef 引用含有 10 个整数的数组
数组的下标是 size_t 类型,一种机器相关的无符号类型,定义在 cstddef 头文件。
char st[12] = "fundamental"; // 使用字符串字面值初始化字符数组,编译器会在最后面加一个空字符
for (size_t i = 0; i < 12; ++i) {
cout << st[i] << endl;
}
多维数组:
int ia[3][4];
int ib[10][20][30] = {0};
int ic[3][4] = {
{0, 1, 2, 3},
{4, 5, 6, 7},
{8, 9, 10, 11}
};
// equivalent initialization without the optional
// nested braces for each row
int ia3[3][4] = {0,1,2,3,4,5,6,7,8,9,10,11};
// explicitly initialize row 0; the remaining elements
// are value initialized
int ix[3][4] = {0, 3, 6, 9};
指针与数组
指针与数组有着非常紧密的联系。使用数组的名字,实际上用的是指向数组首元素的指针!
string nums[] = {"one", "two", "three"};
string *p = &nums[0];
// 等价于
string *p = nums;
vector 和 string 的迭代器支持的运算,数组的指针全部支持!例如递增运算符:++p; // p 指向下一元素
给数组的指针加上整数 n,结果仍然是指针,相比原来指向的元素前进了 n 个位置。
两个指针之间的距离:ptrdiff_t diff = &nums[2] - &nums[0];
对数组的下标运算,实际上是操作指针!
int ia[] = {0, 2, 4, 6, 8};
int i = ia[2];
// 等价于
int *ptr = ia;
int i = *(ptr + 2);
当你明白上面这点之后,你就能明白为什么对指针也能进行下标操作!标准库类型如 vector 和 string 的下标必须是无符号类型,但内置数组的下标运算符可以处理负值。
int *ptr2 = &ia[2];
cout << ptr2[1] << endl; // ia[3]
cout << ptr2[-2] << endl; // ia[0]
我们应该始终使用 C++ 标准库的 vector 和迭代器,避免使用内置数组和指针!!
C 风格字符串
我们应该始终使用 C++ 标准库的 string,而不要使用 C 风格字符串,后者仅仅作为学习了解。
C 风格字符串及相关操作定义在 cstring 文件中,是 C 语言 string.h 的 C++ 版本。
char ca1[] = "hello";
char ca2[] = "world";
cout << strlen(ca1) << endl; // 空字符不计算在内
cout << strcmp(ca1, ca2) << endl; // s1 == s2 返回 0、s1 > s2 返回 正值、s1 < s2 返回负值
cout << strcat(ca1, ca2) << endl;
cout << strcpy(ca1, ca2) << endl;
const char ca[] = {'h', 'e', 'l', 'l', 'o'};
const char *cp = ca;
cout << *cp << endl; // h
cout << cp << endl; // hello
while (*cp) {
cout << *cp << endl;
++cp;
}
表达式、语句
基本概念
表达式由一个或多个运算对象 (operand) 组成,对表达式 (expression) 求值得到一个结果 (result)。
字面值和变量是最简单的表达式,其结果就是字面值和变量的值。
把一个运算符 (operator) 和一个或多个运算对象组合就会生成更复杂的表达式。
作用于一个运算对象的运算符是一元运算符 (unary operator),如取地址符 & 和解引用符 *。
作用于两个运算对象的运算符是二元运算符 (binary operator),如相等运算符 == 和乘法运算符 *。
作用于三个运算对象的运算符是三元运算符,只有 ?:。
函数调用是一种特殊的运算符,对运算对象的数量没有限制。
C++ 的表达式或者是左值 (lvalue),或者是右值 (rvalue)。在 C 语言中这两者的含义是,左值可以位于赋值语句的左侧,右值不能。在 C++ 中,当一个对象被用作右值时,用的是对象的值(内容);被用作左值时,用的是对象的身份(在内存中的位置)。
位运算符
位运算符:~, <<, >>, &, ^, |
请注意,仅将位运算符用于无符号数!
如果运算对象是“小整型”比如 char,则它的值会被自动提升为较大的整型,前面补 0。
一个班级中有 30 个学生,测验的结果是通过或不通过,那么全班的结果可以用一个无符号整数来表示:
// 之所以使用 unsigned long,是因为 int 类型在不同的机器上只能确保占用 16 位,而 long 可以确保至少拥有 32 位
unsigned long quiz1 = 0;
quiz1 |= 1UL << 27; // 第 27 位置为 1,表示学生 27 通过了测验
bool status = quiz1 & (1UL << 27); // 检查学生 27 是否通过测验
sizeof 运算符
sizeof 接受一个类型、或一个表达式,返回 size_t 类型。
Sales_data data, *p;
size_t s1 = sizeof(Sales_data); // Sales_data 类型的对象所占的空间大小
// 等价于
size_t s2 = sizeof data;
// 等价于
size_t s3 = sizeof *p;
size_t s4 = sizeof p; // 指针所占的空间大小,sizeof 不会去解引用指针,即使是无效指针也没有关系
size_t s5 = sizeof data.bookNo;
size_t s6 = sizeof data.units_bold;
size_t s7 = sizeof data.revenue;
// 等价于
size_t s8 = sizeof Sales_data::revenue; // c++ 11 允许使用作用域运算符来获取类成员的大小
// 对数组执行 sizeof 运算,得到整个数组所占空间的大小
// 计算数组中元素的个数
int x[10];
int *p = x;
cout << sizeof(x) / sizeof(*x) << endl; // 10
cout << sizeof(p) << endl; // 8
cout << sizeof(*p) << endl; // 4
cout << sizeof(int) << endl; // 4
对 string 或 vector 执行 sizeof 运算,只返回该类型固定部分的大小,不会计算对象中的元素占用了多少空间。
类型转换
运算符的运算对象,总是转换为最宽的类型,例如位运算中的整型提升。
int ival = 3.14 + 3; // 发生隐式转换
数组自动转换成指向数组首元素的指针,也是一种隐式转换。
int ia[10];
int *ip = ia;
任何具有明确定义的类型转换,只要不涉及 low-level const,都可以使用 static_cast:
int i = 10;
int j = 20;
double slope = i / j;
slope = static_cast<double>(j) / i;
任何非常量对象的地址都能存入 void*:
double d = 3.14;
void *p = &d;
double *dp = static_cast<double*>(p); // ✅ 将 void* 转换回初始的指针类型
const_cast 只能改变运算对象的底层 const,将常量对象转换成非常量对象的行为,称为去掉 const 性质 (cast away the const)。
如果对象本身不是常量,使用 const_cast 获得写权限是合法的行为;如果对象本身是常量,cast away the const 获得写权限、再执行写操作就会产生未定义的后果!const_cast 常常用于有函数重载的上下文中。
const char *pc;
char *p = const_cast<char*>(pc); // 可以编译,但通过 p 写值是未定义的行为,非常危险!
#include <cstdio>
int main() {
const int x = 5;
*(int *)(&x) = 6; // 危险!
printf("%d\n", x); // 5
printf("%d\n", *(&x)); // 6
int *p = const_cast<int*>(&x);
*p = 7; // 危险!
printf("%d\n", x); // 5
printf("%d\n", *p); // 7
}
以下两种是旧式的强制类型转换:
double d = 3.14;
cout << int(d) << endl; // 函数形式的强制类型转换
cout << (int)d << endl; // C 风格的强制类型转换
// 当我们在某处执行旧式的强制类型转换时,如果换成 const_cast 和 static_cast 也合法,则其行为与对应的命名转换一致。
// 如果替换后不合法,则其行为与 reinterpret_cast 类似。
int *ip = &i;
char *ptrc = reinterpret_cast<char*>(ip); // 这是非常危险的!!
跳转语句
C++ 提供了四种跳转语句:break, continue, goto, return。
goto 的作用是从 goto 语句无条件跳转到同一函数内的另一语句。鼓励最好不要使用 goto!别人的代码要会读,自己尽量不要写。
try-catch 与异常处理
#include <stdexcept>
using std::out_of_range;
int main() {
try {
string s("hello world");
cout << s.substr(0, 5) << endl; // prints hello
cout << s.substr(6) << endl; // prints world
cout << s.substr(6, 11) << endl; // prints world
cout << s.substr(12) << endl; // throws out_of_range
} catch (out_of_range) {
cout << "caught out_of_range" << endl;
}
return 0;
}
函数
函数包括四个部分:返回类型、函数名字、形参、函数体。
圆括号 () 称为调用运算符。
函数声明也称函数原型。函数通常在头文件中声明,在源文件中定义。
只存在于块执行期间的对象称为自动对象。普通的局部变量、形参是自动对象。
局部静态对象在程序的执行路径第一次经过对象定义语句时初始化,并且直到程序终止才被销毁。
void test(int i) { // 自动对象
int j; // 自动对象
static size_t ctr = 0; // 局部静态对象
}
参数传递
int fact(int val) { // 隐式地定义并初始化形参,int val = 5
int ret = 1;
while (val > 1) {
ret *= val--;
}
return ret; // 返回,并将控制权交回主调函数
}
fact(5); // 主调函数的执行被中断,被调函数开始执行;用实参 5 初始化函数对应的形参
当形参是引用类型时,实参在函数调用时被引用传递 (passed by reference),引用形参是它绑定的对象的别名。
// 交换两数的引用传递版本
void swap(int &a, int &b) {
int temp = a;
a = b;
b = temp;
}
swap(a, b); // 传引用
当形参不是引用类型,实参的值被拷贝给形参,称为值传递 (passed by value)。改变形参的值并不会改变实参。
// 交换两数的值传递版本
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
swap(&a, &b); // 传值(地址)
// function that takes a pointer and sets the pointed-to value to zero
void reset(int *ip)
{
*ip = 0; // changes the value of the object to which ip points
ip = 0; // changes the **local copy** of ip; the argument is unchanged
}
C 和 ObjC 只有值传递,没有引用传递!C does not support pass-by-reference and Objective-C, being a strict superset of C doesn't either.
使用引用传递避免实参拷贝:拷贝类对象或者容器对象是比较低效的,甚至有的类根本就不支持拷贝操作。
例如,我们想要比较两个 string 的长度,string 可能会非常长,所以我们避免直接拷贝它们。又因为比较长度只读不修改,因此最好把形参定义成对常量的引用。
bool isShorter(const string &s1, const string &s2) {
return s1.size() < s2.size();
}
定义函数形参为引用类型时,使用常量引用,除非需要修改实参的值!这样做有很多好处:1. 调用者清晰地知道,实参的值不可能被修改。2. 可以接受的实参类型大大增加,例如 const 对象、字面值、需要类型转换的对象等。
使用引用形参返回额外信息:一个函数只能返回一个值,然而有时我们执行一个函数希望得到多个结果,这种情景下,引用形参被广泛使用到!
例如我们希望返回 string 对象中某个字符第一次出现的位置,同时返回该字符出现的总次数:
string::size_type find_char(const string &s, char c, string::size_type &occurs) {
size_t ret = -1;
size_t size = s.size();
occurs = 0;
for (size_t i = 0; i < size; ++i) {
if (s[i] == c) {
if (ret == -1) {
ret = i;
}
++occurs;
}
}
return ret;
}
形参的顶层 const 会被忽略!
void fcn(const int i) {}
void fcn(int i) {} // ❌ 重复定义
不允许拷贝数组,所以我们无法以值传递的方式使用数组参数。将数组作为实参传递时,实际上传递的是指向数组首元素的指针。
void print(const int[]);
// 等价于
void print(const int*);
有时我们无法提前预知应该向函数传递几个实参,为了编写处理未知数量实参的函数,有以下几种方法:
- 实参们的类型相同:initializer_list (C++11)
- 实参们的类型不同:可变函数模板(ch16.4 介绍)
- 省略符形参(仅用于访问某些特殊��的 C 代码)
main 函数
main 函数可以从命令行接受参数,声明为:
int main(int argc, char *argv[]) {
// 第一个参数表示数组中字符串的数量
// 第二个参数是一个数组,它的元素是指向 C 风格字符串的指针
// 当实参传递给 main 函数后,argv 的第一个元素指向程序的名字或者空字符串;接下来的元素指向命令行提供的实参。
for (int i = 0; i < argc; ++i) {
string s(argv[i]);
cout << s << endl;
}
return 0;
}
为了使返回值与机器无关,cstdlib 头文件定义了两个预处理变量:EXIT_SUCCESS 和 EXIT_FAILURE。
返回类型和 return 语句
值是如何被返回的?返回值被拷贝到调用点,用于初始化调用点的一个临时变量。
函数可以返回引用,同其它引用类型一样,该引用只是它所引对象的一个别名。
const string &shoterString(const string &s1, const string &s2) {
return s1.size() <= s2.size() ? s1 : s2;
}
// tolower change the argument itself, not a local copy
string &tolower(string &s) {
for (string::size_type i = 0; i != s.size(); ++i)
s[i] = tolower(s[i]);
return s;
}
但不要返回局部对象的引用或指针,因函数完成后它的内存空间也被释放掉。
C++11 列表初始化返回值:
vector<string> process() {
return {"functionX", "okay"};
}
数组不能被拷贝,所以函数不能返回数组。函数可以返回数组的指针或引用。
int (*func(int i))[10];
// 上面的写法显然过于烦琐,可以使用类型别名。
typedef int arrT[10];
arrT* func(int i);
// C++ 11 还可以使用尾置返回类型
// 本来是 returnType 的地方写 auto,并将 returnType 放在 -> 之后
auto func(int i) -> int(*)[10];
函数重载
如果同一作用域内的几个函数名字相同,但形参列表不同,称之为重载函数:
void print(const char *p);
void print(const int *begin, const int *end);
void print(const int ia[], size_t size);
不允许两个函数除了返回类型外的其它要素都相同。
string lookup(const string&);
bool lookup(const string&); // ❌ 重复声明
默认实参
通常在函数声明中指定默认实参,并放在头文件中!
string screen(size_t ht = 24, size_t wid = 80, char backgrnd = ' ');
一旦某个形参被赋予了默认值,它后面的所有形参都要有默认值。
inline 函数
一次函数调用包含了一系列的工作:调用前要先保存寄存器、并在返回时恢复;可能需要拷贝实参;程序转向一个新的位置继续执行。
将函数定义成内联函数,就是将它在每个调用点上像表达式一样地展开,从而消除函数的运行时开销。
inline const string& shorterString(const string &s1, const string &s2) {
return s1.size() <= s2.size() ? s1 : s2;
}
inline 是向编译器发出的一个请求,编译器可以选择忽略。
inline 适用于规模较小、流程直接、频繁调用的函数。
constexpr 函数
constexpr 函数是指能用于常量表达式的函数。
函数的返回类型、所有形参都必须是字面值,且函数体中有且仅有一条 return 语句。
constexpr int new_sz() { return 42; }
constexpr int foo = new_sz();
初始化变量 foo 时,编译器把对 constexpr 函数的调用替换成其结果值。为了能在编译过程中随时展开,constexpr 函数都是隐式内联的。
constexpr 函数不一定返回常量表达式。
constexpr size_t scale(size_t cnt) {
return new_sz() * cnt; // 这个函数返回的不是 constexpr
}
constexpr int a1[scale(2)]{1, 2};
int i = 2;
constexpr int a2[scale(i)]{1, 2}; // ❌ 当函数用在 constexpr 上下文中,编译器会负责检查,如果函数返回结果不是 constexpr,则会报错
inline 函数和 constexpr 函数都要定义在头文件中。
调试帮助
程序中有一些代码只在调试时使用,发布时需要屏蔽这些代码。
assert 是一种预处理宏 (preprocessor marco),也就是预处理变量,由预处理器而非编译器管理。
assert 的行为依赖于 NDEBUG 预处理变量,如果定义了这个变量,assert 将什么也不做。命令行提供 NDEBUG 的方法:clang++ -D NDEBUG main.cpp
int main() {
// assert 0 或 false 会输出信息并终止程序的执行
assert(0);
assert(false);
#ifdef NDEBUG
cout << __func__ << endl; // C++ 编译器为每个函数定义了 __func__,存放函数的名字
// 预处理器还定义了 4 个对调试很有用的名字
cout << __FILE__ << endl; // 文件名
cout << __LINE__ << endl; // 行号
cout << __TIME__ << endl; // 编译时间
cout << __DATE__ << endl; // 编译日期
#endif
return 0;
}
函数指针
函数指针指向的是函数,而非对象。
函数的类型由它的返回类型和形参类型共同决定。
bool lengthCompare(const string &, const string &) { return true; };
要想声明指向这个函数的指针,只需用指针替换函数名即可:
bool (*pt)(const string &, const string &);
注意,(*pt) 圆括号必不可少,否�则的话,声明的就是一个返回类型为 bool* 的函数。
当我们把函数名作为一个值使用时,它自动转换为指针:
bool (*pt)(const string &, const string &) = lengthCompare;
// 等价于
bool (*pt)(const string &, const string &) = &lengthCompare; // 取地址符是可选的
可以直接使用函数指针调用函数,而无须解引用指针:
bool b1 = pt("hello", "goodbye");
// 等价于
bool b2 = (*pt)("hello", "goodbye");
// 等价于
bool b3 = lengthCompare("hello", "goodbye");
虽然形参不可以是函数类型,但却可以是函数指针。以下的声明,形参看上去是函数类型,实际上是指针:
void useBigger(const string &s1, const string &s2, bool pf(const string &, const string &));
// 等价于
void useBigger(const string &s1, const string &s2, bool (*pf)(const string &, const string &));
这样的声明看上去过于冗长,同样地,我们可以使用类型别名:
typedef bool Func(const string &, const string &);
// 等价于
typedef bool (*FuncP)(const string &, const string &);
void useBigger(const string &s1, const string &s2, Func);
// 等价于
void useBigger(const string &s1, const string &s2, FuncP);
虽然不能返回一个函数,但能返回函数指针。然而,必须把返回类型写出指针类型,不可以写函数类型,最简单的方式是使用类型别名。
using PF = int (*)(int *, int);
PF f1(int);
动态内存
目前为止,我们学习的对象都有严格定义的生存期。
- 全局对象在程序启动时分配、在程序结束时销毁。
- 局部自动对象在程序块内被创建、在离开块时被销毁。
- 局部 static 对象在第一次使用前分配,在程序结束时销毁。
静态内存用来保存定义在任何函数之外的变量、局部 static 对象、类的 static 数据成员;栈内存用来保存定义在函数内的非 static 对象;堆内存用来存储动态分配的对象,动态对象的生命期由程序来显式地控制。
直接管理内存
C++ 定义了两个运算符,new 在动态内存中为对象分配空间并返回一个指向该对象的指针;delete 接受一个动态对象的指针,销毁该对象,并释放与之相关的内存。
相对于智能指针,直接使用这两个运算符来管理内存非常容易出错;而且,自己直接管理内存的类与使用智能指针的类不同,它们不能依赖类对象拷贝、赋值、销毁操作的任何默认定义。
确保在正确的时间释放内存是非常关键、但又极其困难的。忘记释放内存会造成内存泄漏;在尚有指针引用内存时就释放了它,又会产生引用非法内存的指针。
int main() {
// 在堆区分配的内存是无名的,new 无法为其分配的对象命名,而是返回一个指向该对象的指针
int *p1 = new int;
// 默认情况下,动态分配的对象是默认初始化的
// 也就是说,内置类型或组合类型的对象的值是未定义的;类类型对象将用默认构造函数进行初始化
// 我们也可以使用直接初始化、或者 C++11 的列表初始化
int *p2 = new int(1024);
string *ps = new string(10, 'c');
vector<int> *pv = new vector<int>{0, 1, 2, 3, 4, 5};
// pointer to const
const string *pcs = new const string("hello");
// delete 执行两个动作:销毁指针指向的对象,释放对应内存
delete p1; // pi 必须指向一个动态分配的对象或是空指针,释放非 new 分配的内存、或是相同的指针值被释放多次,其行为都是未定义的!
delete p2;
delete ps;
delete pv; // frees the memory for the vector, which also destroys the elements in that vector
// 当我们 delete 一个指针后,指针值就变为无效了
// 虽然指针已经无效,但在很多机器上,指针仍然保存着(已经释放了的)动态内存的地址
// delete 之后的指针变成了人们所说的空悬指针 (dangling pinter),即指向一块曾经保存数据对象但现在已经无效的内存的指针
cout << pcs << endl;
delete pcs;
cout << pcs << endl;
cout << *pcs << endl;
// 如果我们需要保留指针,可以在 delete 之后赋予 nullptr,清楚地指出指针不指向任何对象
pcs = nullptr;
cout << pcs << endl;
return 0;
}
一旦程序用光了堆内存,new 表达式就会失败:
int *p1 = new int; // if allocation fails, new throws std::bad_alloc
int *p2 = new (nothrow) int; // if allocation fails, new returns a null pointer
返回指向动态内存的指针(而不是智能指针)的函数,调用者必须负责释放内存:
// factory returns a pointer to a dynamically allocated object
Foo *factory(T arg) {
// process arg as appropriate
return new Foo(arg); // caller is responsible for deleting this memory
}
函数的退出有两种可能,正常结束返回或者发生了异常。下面的例子中,一旦发生异常,ip 指针指向的内存永远也无法释放,造成内存泄漏。
void f() {
int *ip = new int(42);
throw runtime_error("error");
delete ip; // 函数 f 以外没有指针指向这块内存
}
一种简单而有效的确保资源被释放的方法是使用智能指针。
智能指针
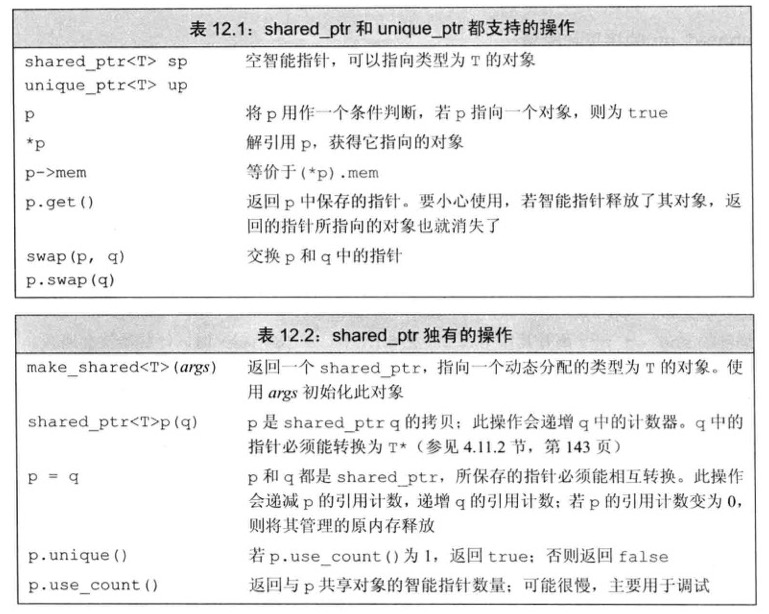
为了更容易、更安全地使用动态内存,C++11 新标准库提供了两种智能指��针:shared_ptr 允许多个指针指向同一个对象;unique_ptr “独占”所指向的对象,它们都定义在 memory 头文件中。智能指针的行为类似常规指针,重要的区别是它负责自动释放所指向的对象!
另外,weak_ptr 是一种弱引用,它指向 shared_ptr 所管理的对象。
C++11 中,最安全的分配和使用动态内存的方法是调用 make_shared,在动态内存中分配一个对象并初始化它。
shared_ptr<int> p1 = make_shared<int>(42);
类似 vector,智能指针也是类模板。可以认为每个 shared_ptr 都有与之关联的“引用计数器”。拷贝一个 shared_ptr 会使引用计数增加;shared_ptr 的析构函数会递减所指对象的引用计数,一旦对象的引用计数变为 0,shared_ptr 的析构函数就会销毁对象,并释放它占用的内存。
我们可以用 new 返回的内置指针,来初始化智能指针。但要注意,这个构造函数是 explicit 的,意味着它不接受隐式转换。
shared_ptr<int> p1(new int(42));
shared_ptr<int> p2 = new int(42); // ❌
默认情况下,用来初始化智能指针的普通指针,必须是指向动态内存的,因为智能指针默认也是使用 delete 运算符来释放它关联的对象。我们可以将智能指针绑定到一个指向其它类型的资源的指针上,但要这么做,必须提供自己的操作来代替 delete(例如下面提到的动态数组)。
unique_ptr 与 shared_ptr 不同,没有类似 make_shared 的标准库函数返回一个指针,当我们定义 unique_ptr 时,需要将其绑定到一个 new 返回的指针上。类似 shared_ptr,初始化 unique_ptr 必须采用直接初始化的形式。
unique_ptr<double> p;
unique_ptr<string> p1(new string("Stegosaurus"));
unique_ptr<int> p2(new int(42));
string *s = p1.get(); // Pointer to the managed object or nullptr if no object is owned.
cout << *s << '\n';
unique_ptr “占有”它指向的对象,不支持赋值、拷贝操作,但可以通过 release 或 reset 将指针的所有权转移。
unique_ptr<string> p3(p1.release()); // p1 放弃对指针的控制权,返回指针,并将 p1 置为空
unique_ptr<string> p4(new string("Trex"));
p3.reset(p4.release()); // 释放 p3 指向的内存;p3 指向 p4 指向的内存,p4 置为空
reset is a member function of std::shared_ptr and std::unique_ptr used to release ownership of the current allocated memory (if any) and set the smart pointer to manage a new object (if provided).
创建 weak_ptr 要用一个 shared_ptr 来初始化它:
shared_ptr<int> p = make_shared<int>(42);
weak_ptr<int> wp(p);
// 访问弱引用对象
if (shared_ptr<int> np = wp.lock()) {
cout << *np << endl;
}
动态数组
new 和 delete 运算符一次分配/释放一个对象,但如 vector 和 string 都是在连续内存中保存元素,当容器需要重新分配内存时,必须一次性为很多元素分配内存。
注意,绝大多数应用都没有直接访问动态数组的需求,使用标准库的容器是更简单、更安全的选择!
C++ 语言和标准库提供了两种一次性分配一个对象数组的方法,分别是 new 表达式语法和 allocator 类。
int *pia = new int[42]; // pia points to the first of these ints
delete [] pia; // brackets used to delete pointer to element in an array
unique_ptr 可以用于管理 new 分配的数组:
// up points to an array of ten uninitialized ints
unique_ptr<int[]> up(new int[10]);
for (size_t i = 0; i != 10; ++i)
up[i] = i; // assign a new value to each of the elements
up.release(); // automatically uses delete[] to destroy its pointer
shared_ptr 不直接支持管理动态数组,如果希望如此,必须定义自己的删除器:
void deleter(int *p) { delete[] p; }
// to use a shared_ptr we must supply a deleter
shared_ptr<int> sp(new int[10], deleter);
// shared_ptrs don't have subscript operator
// and don't support pointer arithmetic
for (size_t i = 0; i != 10; ++i)
*(sp.get() + i) = i; // use get to get a built-in pointer
sp.reset(); // uses the function we supplied
// that uses delete[] to free the array
new 运算符将分配内存和对象构造组合在了一起;delete 将对象析构和内存释放组合在了一起。在分配动态数组的内存时,我们通常希望将内存分配和对象构造分离,标准库 allocator 帮助我们实现这一点,它提供一种类型感知的内存分配方法,它分配的内存是原始的、未构造的。
const size_t n = 100;
allocator<string> alloc; // object that can allocate strings
string *p = alloc.allocate(n); // allocate n unconstructed strings
string *q = p; // q now points to the first element
// pre-C++ 11 alloc.construct must be explicitly passed an object of
// the allocated type, so, we pass an empty string() explicitly
alloc.construct(q++, string()); // *q is the empty string
// C++ 11, pass string constructor
alloc.construct(q++, string("hi")); // *q is hi!
// 用完之后要对每个元素调用 `destroy` 来析构,然后释放内存
for (q = p + size - 1; q != p; --q)
alloc.destroy(q); // free the strings we allocated
alloc.deallocate(p, n); // return the memory we allocated
操作符重载
重载的操作符是具有特殊名字的函数:它们的名字由关键字 operator 和后面跟着的运算符号共同组成。
对于二元运算符来说,左侧运算对象传递给第一个参数,右侧运算对象传递给第二个参数。
// 声明
friend std::ostream& operator<<(std::ostream&, const Sales_item&);
// 使用
std::cout << item;
如果一个运算符是成员函数,则运算符的左侧运算对象绑定到隐式的 this 指针。
Sales_item& operator+=(const Sales_item&);
注意,运算符函数或者是类的成员函数,或者至少含有一个类类型的参数。不能重定义两个内置类型例如 int 的运算符!
函数调用运算符
struct absInt {
int operator()(int val) const {
return val < 0 ? -val : val;
}
};
int main() {
int i = -42;
absInt absObj; // object that has a function-call operator
unsigned ui = absObj(i); // passes i to absObj.operator()
cout << i << " " << ui << endl;
return 0;
}
命名空间
内联命名空间中的名字可以被外层命名空间直接使用。
namespace cpp_primer {
inline namespace FifthEd {
}
}
namespace 关键字后紧跟花括号的是未命名的命名空间。
未命名的命名空间中定义的变量具有静态生命周期——在第一次使用时创建,在程序结束时销毁。
未命名的命名空间仅在特定的文件内部有效,不能跨越多个文件,但在文件内可以不连续。
如果一个头文件定义了未命名的命名空间,则该命名空间中定义的名字,将在每个包含了该头文件的文件中对应不同的实体。
using 声明:
#include <iostream>
using std::cin;
using std::cout;
using std::endl;
特殊工具
union
union(共用体)是一种特殊的类。它的所有数据成员都共用同一块内存。union 的存储空间至少要能容纳它的最大的数据成员。
union 不能含有引用类型的成员。
union Date {
int year; // 4字节
char month; // 1字节
char day; // 1字节
}; // 共用一块4字节内存
int main(int argc, const char * argv[]) {
union Date date;
date.year = 2012;
printf("%d\n", date.year);
// date = (year = 2012, month = '\xdc', day = '\xdc')
// 2012的十六进制是0x7DC,整体内存变成DC 70 00 00
date.month = 12;
printf("%d\n", date.month); // 12
// date = (year = 1804, month = '\f', day = '\f')
// \f换页符,在ASCII码表中的十进制值是12
// char是单字节,Date的最后一个字节被写入0C,整体内存变成0C 70 00 00
date.day = 12;
printf("%d\n", date.day); // 12,内存0C 70 00 00
return 0;
}
bit-field
A class can define a (non static) data member as a bit-field. A bit-field holds a specified number of bits.
Ordinarily, we use an unsigned type to hold a bit-field.
We indicate that a member is a bit-field by following the member name with a colon and a constant expression specifying the number of bits:
typedef unsigned int Bit; // Bit 这种类型占 64 位
class File {
Bit mode: 2; // mode has 2 bits
Bit modified: 1; // modified has 1 bit
Bit prot_owner: 3; // prot_owner has 3 bits
Bit prot_group: 3; // prot_group has 3 bits
Bit prot_world: 3; // prot_world has 3 bits
}
Bit-fields defined in consecutive order within the class body are, if possible, packed within adjacent bits of the same integer, thereby providing for storage compaction.
For example, in the preceding declaration, the five bit-fields will (probably) be stored in a single unsigned int. Whether and how the bits are packed into the integer is machine dependent.
The address-of operator (&) cannot be applied to a bit-field, so there can be no pointers referring to class bit-fields.
参考资料:C++ Bit Fields | Microsoft Docs
我们可以用单字节的类型,按位存放布尔值,然后通过位运算来存/取:
#define ZERO_MASK (1 << 0) // 表示最低位
#define ONE_MASK (1 << 1)
#define TWO_MASK (1 << 2)
#define THREE_FOUR_MASK (0b11 << 3) // 如果一个数据需占 2 bits,那么它的掩码要相应地用两位
// 将布尔值打印成字符串
void printb(bool b) {
printf("%s\n", b ? "true" : "false");
}
int main(int argc, const char * argv[]) {
// 按位存放,最多可存放8个布尔值,这个例子中我们存3个,从最低位开始存
char bits = 0b00000000;
// 取值
// !! 表示转为 bool 类型
bool b2 = !!(bits & TWO_MASK);
printb(b2); // false
// 设为true
bits |= TWO_MASK; // 位或运算,会把对应位变成1
b2 = !!(bits & TWO_MASK); // 位与的结果是4,按照布尔值的定义,非0为true,只有全为0才为false
printb(b2); // true
// 设为false
bits &= ~TWO_MASK; // 掩码取反,再进行位与运算,会把所有位都变成0
b2 = !!(bits & TWO_MASK); // 所有位都是0
printb(b2); // false
return 0;
}
上面的代码可读性较差,因为其他人不知道每一位存储的布尔值代表什么含义,我们可以用 union 和 bit-field 结合的方式,来增加可读性:
union {
char bits;
struct {
unsigned char isRed : 1;
unsigned char isGreen : 1;
unsigned char isBlue : 1;
}; // 相当于增加了可读性,通过变量名告诉读者每一位存储的信息,把这个结构体删掉也完全没有影响
} bits_u;
int main(int argc, const char * argv[]) {
bits_u.bits = 0b00000000; // 注意,调用时还是用bits
bool b2 = !!(bits_u.bits & TWO_MASK);
printb(b2); // false
// 设为true
bits_u.bits |= TWO_MASK;
b2 = !!(bits_u.bits & TWO_MASK);
printb(b2); // true
// 设为false
bits_u.bits &= ~TWO_MASK;
b2 = !!(bits_u.bits & TWO_MASK);
printb(b2); // false
return 0;
}